2025.3.12
1. Set / Map
- Red-Black tree
: self-balancing binary search tree - set, map은 binary search tree의 형태로 이루어져있으며, 실제로 정렬된 상태는 아님
- (=> vector 기반인 pq가 더 빠를 수 있음. set, map은 node 기반임.)
- 때문에 삽입, 삭제, 검색 과정은 binary search tree의 기준을 따르나
- iterator를 활용해 compare기준 순서대로 순회 가능하다
| SET | MAP (key를 기준으로 함. value는 +@느낌) |
| set : (key) 중복 X | map : (key, value) 중복 X |
| multiset : (key) 중복 O | multimap : (key, value) 중복 O |
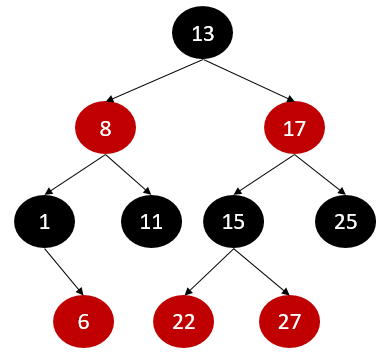 |
 |
| Space | Search | Insert | Delete | |
| Average | O(n) | O(log n) | O(log n) | O(log n) |
| Worst Case | O(n) | O(log n) | O(log n) | O(log n) |
2. Binary search tree
| binary tree (이진트리 : 자식이 두개 이하인) left child : 작은값 right child :큰 값 search time complex : worst case O(n) |
 |
|
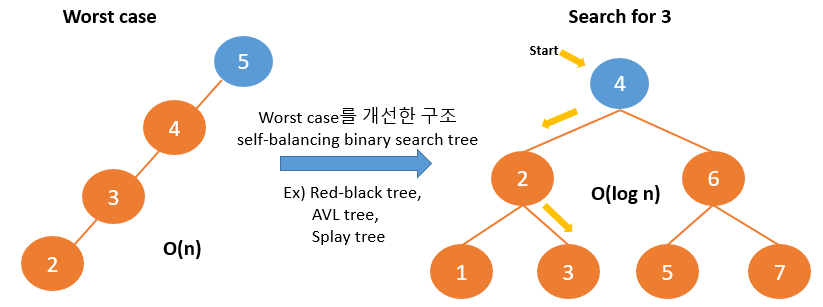 |
||
입력에 따라 성능차이가 크기 때문에 가지를 적절하게 분배해주는 것이 필요함.
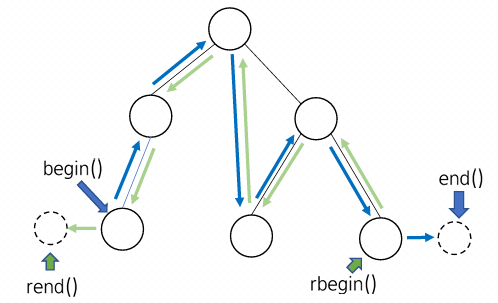
3. Iterator
- Bi-directonal iterator
노드가 지워지지 않는 한 iterator는 유효함. (list, set, map 동일특성)
id별로 검색/삭제가 빈번할 시 iterator 기록 활용이 필수적
4. Set 문법
template<
class Key,
class Compare = std::less<Key>
class A;;ocator = std::allocator<Key>
> class set;set <T> s
set <T, compare<T>> s
iterator s.begin(), s.end()
iterator s.rbegin(), s.rend()
bool s.empty()
void s.clear()
size_t s.size()
size_t s.count(T x) // 1, 0 (중복이 불가능하니까 특정 key값이 있으면 1 없으면 0임)
iterator s.find(T x) // 없으면 end()반환
/* algorithm의 find도 가능하나 자체적으로 있는 find가 더 효율적임.
algorithm의 find는 iterator를 기준으로 순회 돌면서 찾아 O(n)이지만
set의 find(member 함수)는 tree기준으로 검색해서 O(log n)ㅇ 이라 보다 효율적! */
iterator s.lower_bound(T x) // 특정 값 이상을 초과하는 것 중 가장 작은 것
iterator s.upper_bound(T x) // 특정 값 이하의 미만 중 가장 큰 것
pair<iterator, bool> s.insert(x) // insert 성공 여부 반환
// 등록된 iterator면 실행 실패라 false (0) 등록 성공시 true (1)
void s.insert(iterator fisrt, iterator last)
iterator s.erase(iterator pos) // O(1), 있으면 지우고 없으면 무시함
iterator s.erase(iterator fisrt, iterator last) // O(dist(first,last))
//마지막 지워진 element의 다음 iterator 반환함
bool s.erase(T x) // O(log n), 성공 여부 반환
4-1. Set example
compare 기준 : default less<int>, 오름차순
set<int> s;
for(int i = 5; i>0; i--) s.insert(i);
for(auto x : s) cout << x << ' '; // 1 2 3 4 5
for(auto it = s.begin(); it != s.end(); ++it) cout << *it << ' '; // 1 2 3 4 5
for(auto it = s.rbegin(); it != s.rend(); ++it) cout << *it << ' '; // 5 4 3 2 1
s.empty(); // 0
s.size(); // 5
s.count(1); // 1
s.count(0); // 0
auto ret = s.find(1); // 1 검색, ret : 값 1의 iterator
auto ret = s.insert(6); // 6 등록, ret.first : 등록된 iterator, ret.second : 1 (등록여부)
auto ret = s.insert(1).first; // 1 등록, ret : 등록된 iterator
auto ret = s.insert(1).second; // 1 등록, ret : 0 (등록여부)
auto ret = s.erase(2); // 2 삭제, ret : 1 (삭제 여부)
auto ret = s.erase(2); // 2 삭제, ret : 0 (삭제 여부)
auto ret = s.erase(s.begin()); // 맨 앞 element 삭제, ret : 삭제된 element의 다음 iterator
auto ret = s.erase(--s.end()); // 맨 뒤 element 삭제, ret : 삭제된 element의 다음 iterator
5. Compare 설정방법
#Function Object 으로 설정
1) pre- defined function object
- less<T> : 오름차순
template<class T>
struct less{
bool operator()(const T& l, const T& r)const{ // 참조자&는 권장 const는 필수
return l < r;
}
}
- greater<T> : 내림차순
template<class T>
struct greater{
bool operator()(const T& l, const T& r)const{
return l > r;
}
}
// 예시
set<int, greater<int>> s{1, 2, 3, 4, 5};
for(auto x : s) cout << x << ' ' ; // 5 4 3 2 1
2) user- defined function object
- int 절대값 오름차순
struct AbsComp{
bool operator()(const T& l, const T& r)const{
if(abs(l) != abs(r)) return abs(l) < abs(r);
return l < r;
}
};
// 예시
set<int, AbsComp> s{-5, -3, 1, 4, 6};
for(auto x : s) cout << x << ' ' ; // 1 -3 4 -5 6
5-1. Compare 설정 - custom data ver
1) default - less<T> 활용 (operator < overloading 필요)
struct Data{
int a, b, c;
bool operator<()(const T& r)const{ // 참조자&는 권장 const는 필수, 설정한 operator만 사용가능
return a < r.a;
//형태가 같아야함. a<b (errer) a < r.a (O) b < r.b (O) a+b < r.a+r.b (O)
}
};
set <Data> s; // == set<Data, less<Data>>s;
2) user- defined function object
struct Data{ int a, b, c;};
struct Comp{
bool operator()(const T& l, const T& r)const{
return l.a < r.a;
// 이렇게 설정하면 a만 다르면 다른거고, a만 같아도 중복으로 처리됨.
}
}
set<Data, Comp>s;== 설정 필요 없음. 오로지 compare 기준으로 탐색함
=> compare 기준 : a 값 오름차순
key 값 중복 판별 : b, c 관계 없이 a가 같으면 중복 (= key값의 중복은 철저하게 compare 기준으로만 판별함.)
{1, 2, 3} == {1, 0, 0} {1, 2, 3} != {0, 2, 3}
5-2. 우선순위 판별
- compare기준으로 우선순위 높은 값, 낮은 값, 같은 값 모두 판별
- 값 A, B에 대해
- comp (A, B) && ! comp (B, A) : A(left), B(right)
- ! comp (A, B) && comp (B, A) : B(left), A(right)
- ! comp (A, B) && ! comp (B, A) : A == B : Key 값 중복
- 따라서 compare가 만족해야하는 requirement 존재 (strict weak ordering)
+++++++++++++++++++++

6. map 문법
template<
class Key,
class T,
class Compare = std::less<Key>
class A;;ocator = std::allocator<srd::pair<const Keu, T>>
> class map;map <T, U> m
map <T, U, compare<T>> m
U m[T x] // key 값이 x인 value반환. 없으면 0으로 등록
// 배열 index operator!!
// insert보다 이 방법을 많이 씀.
// insert는 기존에 key값이 있으면 새로 입력되는 거를 무시하지만(value무관) index쓰면 value값 변경이 가능함
iterator m.begin(), m.end()
iterator m.rbegin(), m.rend()
bool m.empty()
void m.clear()
size_t m.size()
size_t m.count(T x)
iterator m.find(T x)
iterator m.lower_bound(T x)
pair<iterator, bool> m.insert({T x, U y}) // first(등록된 iterator), second(성공여부)
// 등록된 iterator면 실행 실패라 false (0) 등록 성공시 true (1)
void m.insert(iterator fisrt, iterator last)
iterator m.erase(iterator pos)
iterator m.erase(iterator fisrt, iterator last) // O(dist(first,last))
//마지막 지워진 element의 다음 iterator 반환함
bool m.erase(T x) // 성공 여부 반환
6-1. map example
key 값에 대한 value값 추가된 것 외에 set과 동일
compare 기준은 무조건 key 값
map<int,int> m;
for(int i = 5; i>0; i--) m.insert({i, 0});
// (1,0) (2,0) (3,0) (4,0) (5,0)
for(auto x : m) cout << x.first << ',' << x.second;
for(auto it = m.begin(); it != m.end(); ++it) cout << it->first << ',' << it->second;
// (5,0) (4,0) (3,0) (2,0) (1,0)
for(auto it = m.rbegin(); it != m.rend(); ++it) cout << it->first << ',' << it->second;
m[1] = 3; // (1,3) (2,0) (3,0) (4,0) (5,0)
m[6]; // index 접근시, 등록되어 있지 않은 key 값이면 default 값(0) 으로 insert : (6, 0)
m[7]++; // key값 7이 등록되어 있지 않으므로 value 0 으로 insert 후 value 1 증가 : (7, 1)
// m : (1,3) (2,0) (3,0) (4,0) (5,0) (6,0) (7, 1)
7. multuset, multimap
- equal_range 활용 : 원하는 key값의 범위 [first - second)
- auto ret = m.equal_rangr(x);
- ret.first = m.lower_bound(x);
- ret.second= m.upper_bound(x);
- auto ret = m.equal_rangr(x);
- m.find(x) : x중 하나의 iterator 반환(가장 먼저 만나는, 앞인지 뒤인지는 모름)
- m.erase(m.find(x)) : x인 한 개의 원소 제거, iterator로 지우는 방법
- [] operator 제공X (multi_map) : bool type 아님. 오로지 iterator type으로 반환
8. 정리 (set, map 특징)
- key 값을 이용하여 compare기준으로 정렬 (compare는 function object으로 설정)
- key값은 변경 불가 (필요시 erase 후 insert)
- map의 value값은 변경 가능
- 모든 검색 관련 작업은 오로지 Key 값으로만 진행
- set은 key값만 존재, map은 key 값에 대한 상태 존재
- element가 erase되지 않는 한 iterator는 항상 유효!
'C++ > STL' 카테고리의 다른 글
| [STL] Unordered_set, map (Hash) (0) | 2025.06.18 |
|---|---|
| [STL] Priority Queue(2) - Lazy Update (1) | 2025.06.17 |
| [STL] Priority Queue(1) - heap, sort, compair 설정 (0) | 2025.06.16 |
| [STL] Stack, Queue (0) | 2025.06.13 |
| [STL] String (0) | 2025.06.13 |